Mastering Pivot Functions in AWS Redshift SQL for Data Analysis
Written on
Chapter 1: Introduction to Pivot Functions
If you frequently engage with Amazon Redshift, understanding essential functions can significantly streamline your workflow. One such function is the PIVOT and UNPIVOT, which simplifies the process of transforming a table. A pivot table allows for the effective structuring, summarizing, and analyzing of data presented in tabular form without altering the original dataset.
Here’s a simple example to illustrate this:
WITH win_in_years AS
(SELECT 1 as year, 100 as win
UNION ALL
SELECT 2 as year, 50 as win
UNION ALL
SELECT 3 as year, 200 as win)
SELECT * FROM win_in_years;
The output from this query would look something like this:
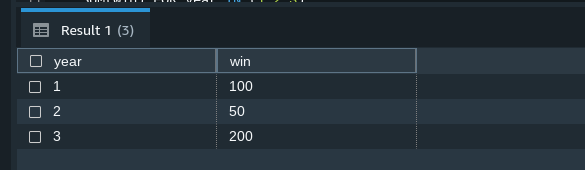
Result — Image by Author
Next, if you wish to rearrange the years as columns and aggregate the profits, you can use the following SQL command:
WITH win_in_years AS
(SELECT 1 as year, 100 as win
UNION ALL
SELECT 2 as year, 50 as win
UNION ALL
SELECT 3 as year, 200 as win)
SELECT *
FROM (SELECT * FROM win_in_years) PIVOT (
SUM(win) FOR year IN (1, 2, 3)
);
This will yield the following result:
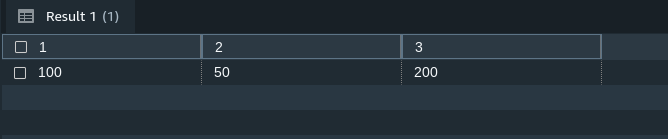
Result — Image by Author
The PIVOT function proves to be an invaluable tool for data analysts and scientists, facilitating easier data evaluation. Data engineers can also leverage this functionality to preprocess data and create new tables as needed. It’s worth noting that AWS has recently introduced support for these SQL operators.
Chapter 2: Practical Applications of PIVOT
In the first video, "Pivot for Redshift Database," viewers will learn practical applications of the PIVOT function within Amazon Redshift, demonstrating how to effectively manipulate and analyze data.
The second video, "Three Amazing SQL Functions in PostgreSQL and Amazon Redshift," covers essential SQL functions that can enhance your data querying capabilities, including advanced uses of PIVOT.