Unlocking the Power of Kafka Connectors: A Comprehensive Guide
Written on
Introduction to Kafka Connectors
Apache Kafka has emerged as the leading event streaming framework as of 2022. According to Stack Overflow's 2022 Developer Survey, it ranks second among the highest-paying frameworks and libraries. With new opportunities arising continuously, it's essential for developers to embrace this technology now.
Understanding the Top-Paying Libraries and Frameworks in 2022
In this blog series, we have previously covered the fundamentals of Apache Kafka and provided hands-on experience. For those unfamiliar with Kafka concepts, please refer to the following resources:
- A Gentle Introduction to Event Streaming — Apache Kafka
- Apache Kafka for Beginners — Learn Kafka by Hands-On
In this article, we will focus on a crucial component of Apache Kafka: Connectors. We'll explore their purpose, functionality, and how to implement them in your projects.
What Exactly are Kafka Connectors?
To grasp the concept of Kafka Connectors, it's beneficial to refer to their definition in the official documentation. Kafka Connectors are pre-built components designed to facilitate the import of data from external systems into Kafka topics, as well as the export of data from Kafka topics to external systems.
To break this down further, Apache Kafka serves as a framework for event streaming, where events are organized in streams that can be produced, consumed, or processed. In contrast, technologies such as databases, cloud services, search indexes, file systems, and key-value stores do not operate on an event-driven basis; they store passive data that isn't updated by events and doesn't generate any.
The only way to bridge the gap between these two fundamentally different systems is through connectors. They act as a liaison, ensuring compatibility between event streaming and non-event streaming technologies. Thanks to Connectors, data can be efficiently streamed into Kafka from various sources and out to multiple targets.

Types of Connectors: Source and Sink
Connectors are categorized based on their functionality into two types: Source Connectors and Sink Connectors.
- Source Connectors: These are responsible for ingesting data from external sources and publishing it to the Kafka Cluster.
- Sink Connectors: These update external data sources by consuming events from specific topics within the Kafka Cluster.
Popular Kafka Connectors
A wide array of Kafka Connectors are available for free online, with many more that can be developed as needed. Some of the most commonly used Kafka Connectors include:
- Debezium Connector
- JDBC Connector
- Amazon S3 Sink Connector
- Google BigQuery Connector
Kafka Connect vs. Connectors
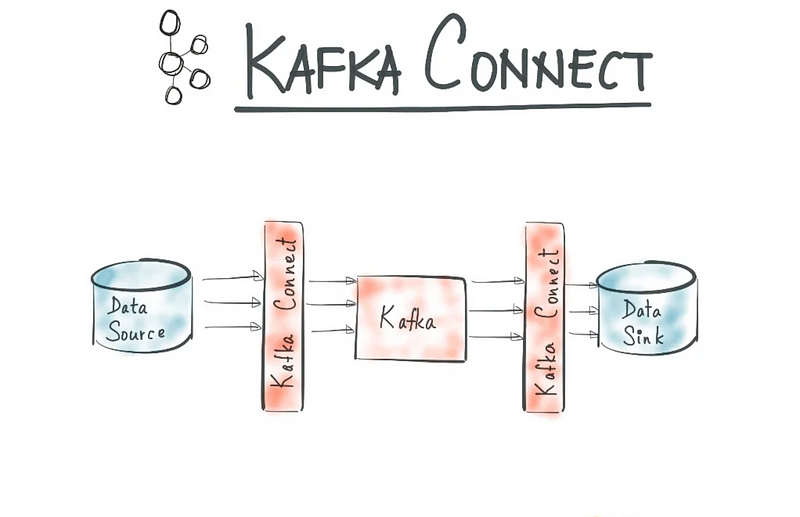
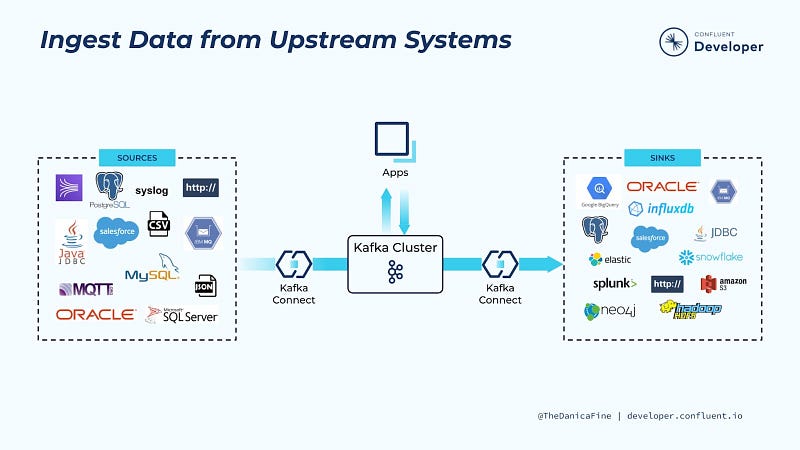
Kafka Connect is a framework designed to integrate Kafka with external systems such as databases, key-value stores, search indices, and file systems, using Connectors. The following diagram illustrates the relationship between connectors and Kafka Connect.
Conclusion
This article provided an overview of the fundamentals of Kafka Connect and its Connectors. In future articles, we will implement the concepts discussed here.
The first video titled "From Zero to Hero with Kafka Connect" offers an engaging introduction to Kafka Connect and its capabilities.
The second video, "Building Your First Connector for Kafka Connect," guides viewers through the process of creating a connector from scratch.
You can connect with me on Twitter here.